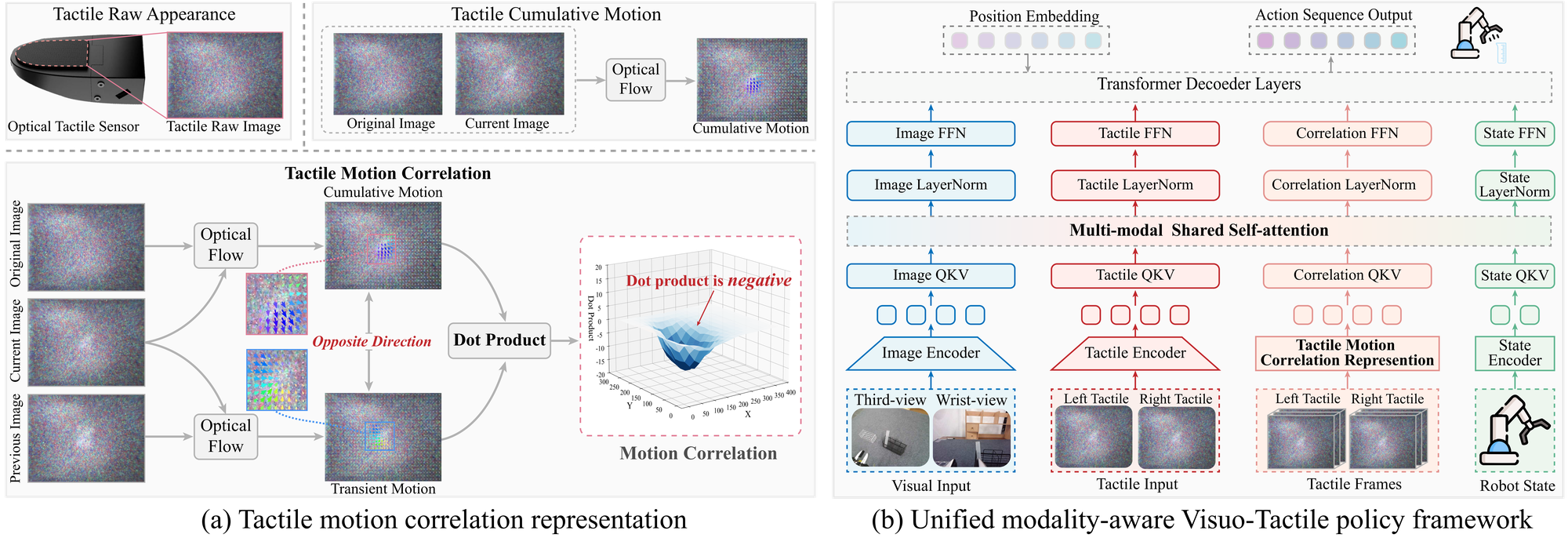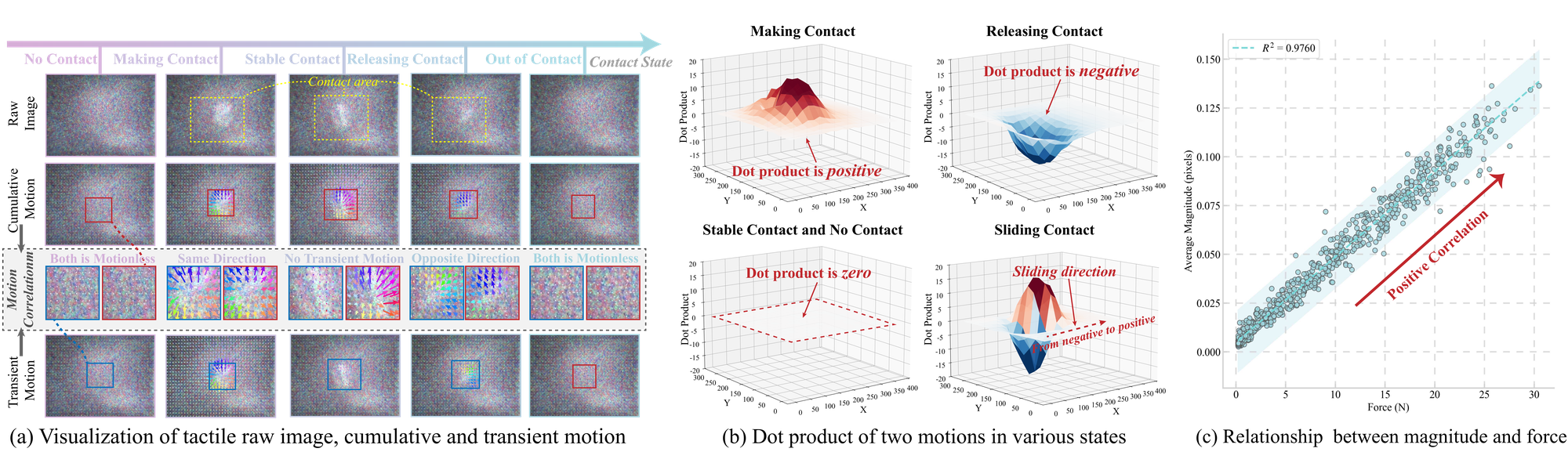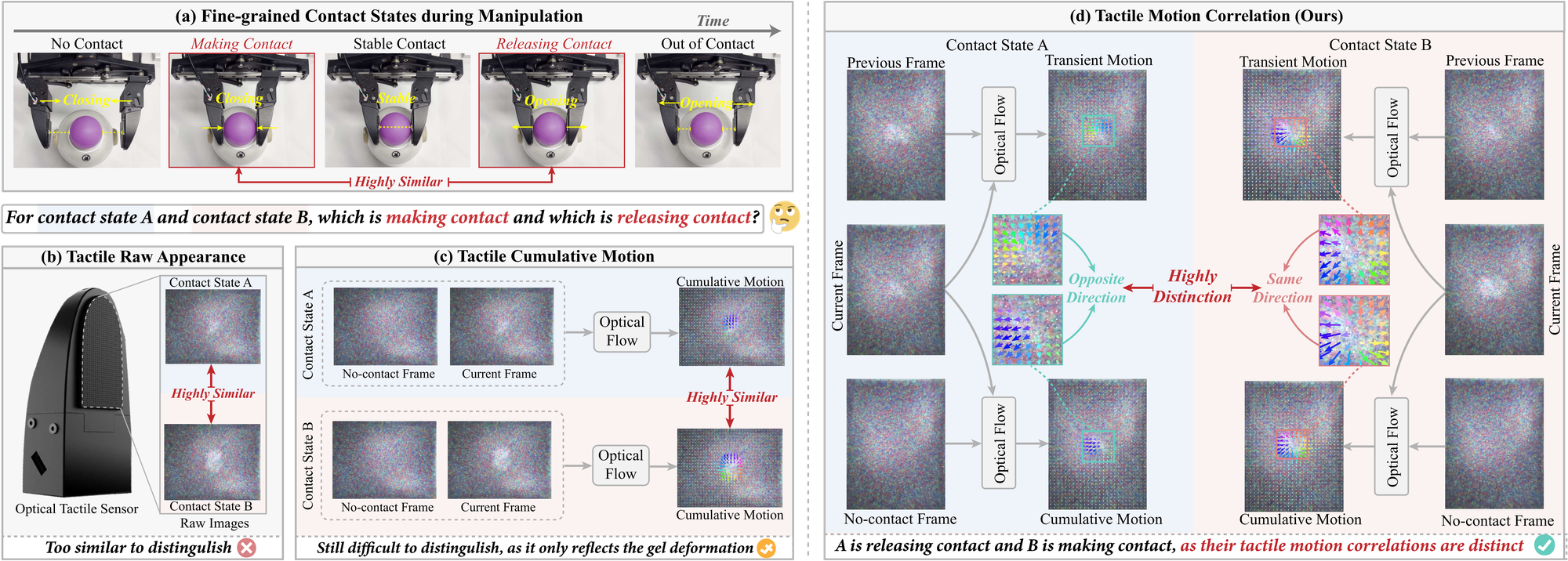
Tactile Motion Correlation (TMC). Fine-grained contact states such as making contact and releasing contact look nearly identical in raw tactile images and even in cumulative motion. By correlating transient and cumulative motion (same vs. opposite direction), TMC explicitly resolves this ambiguity, providing highly discriminative cues for contact-rich manipulation.